arXiv preprint, 2026
Your Language Model is Its Own Critic: Reinforcement Learning with Value Estimation from Actor's Internal States
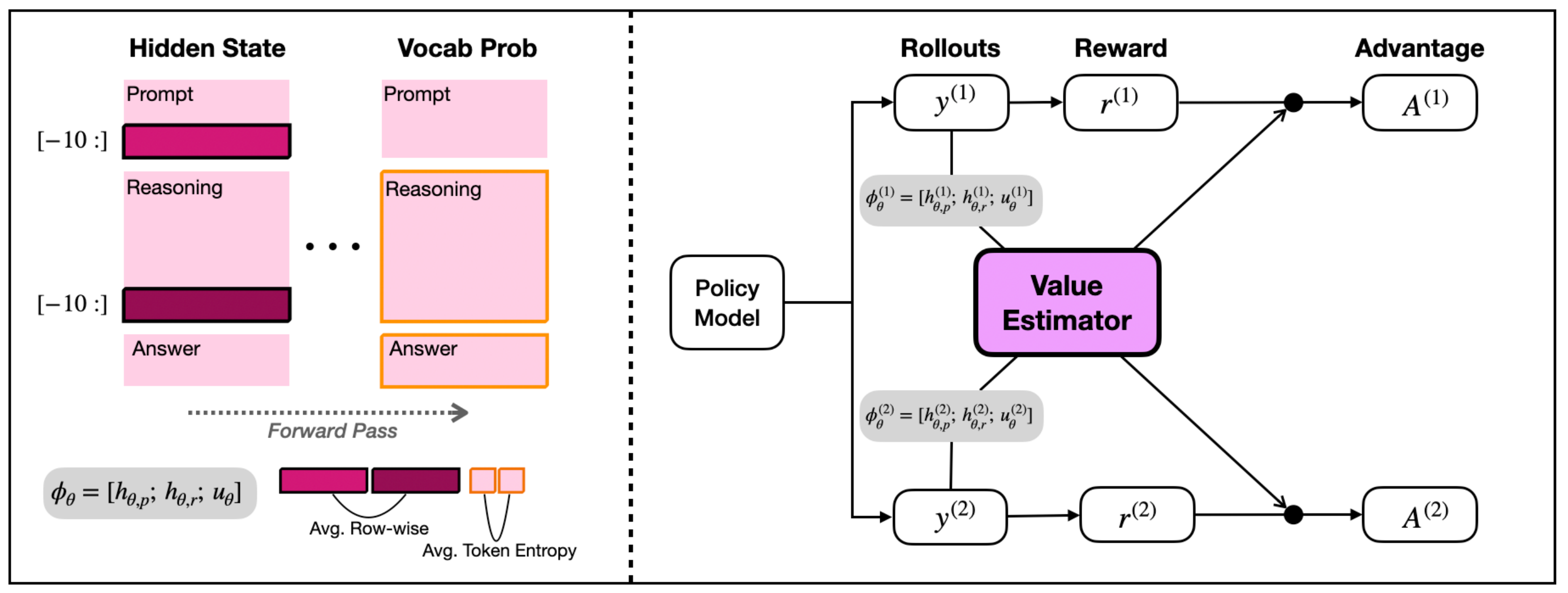
POISE estimates RLVR baselines from the actor's internal hidden states and entropy statistics, reducing rollout overhead while matching DAPO-level performance.